Workers
A Cycloid worker is an essential component that executes the tasks defined in a pipelines. You can have one or several workers, the number of workers and CPU/memory sizing could vary based on the tasks you are going to execute.
There are several ways to deploy your own workers, it can differ a bit if you subscribe to Cycloid Platform:
- SaaS console console.cycloid.io
- Dedicated or On-premises setup
All methods rely on the source code of the public stack-external-worker.
Prerequisites
In terms of network, workers initiate the connection with the scheduler:
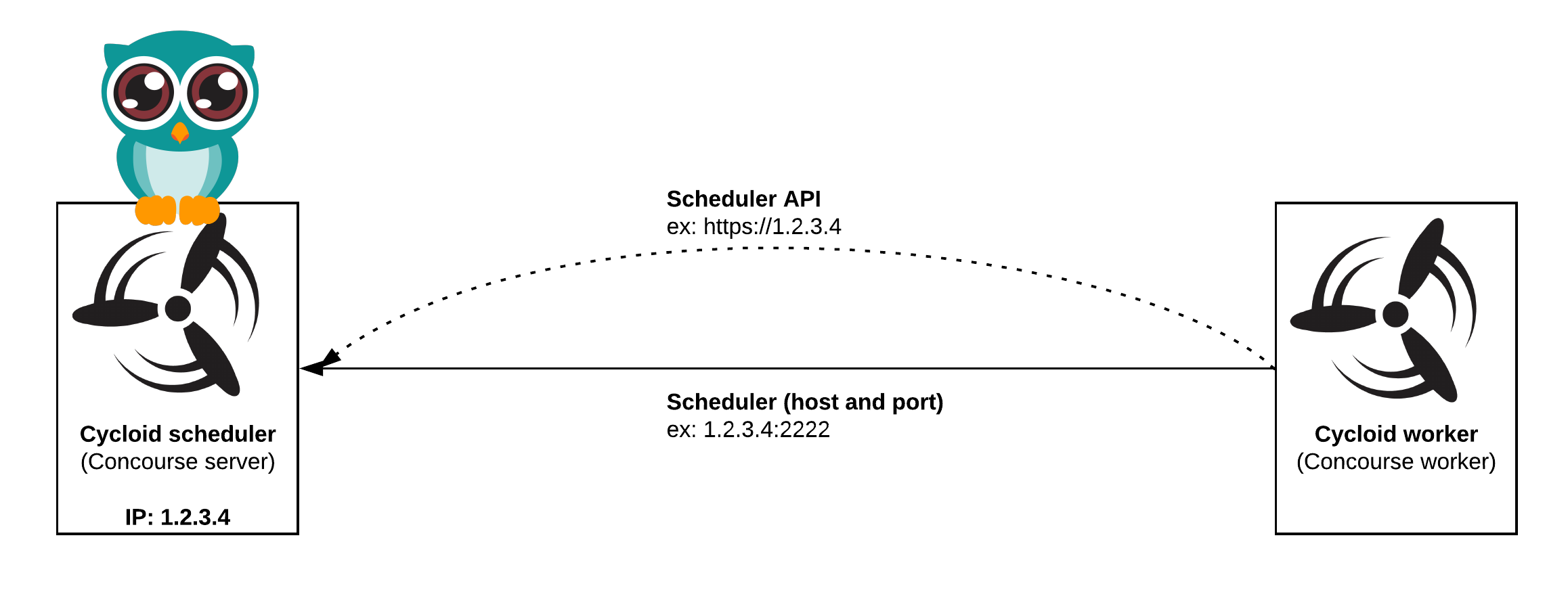
This means if the worker is running in your own private network, there is no inbound network traffic to allow. A common scenario is to deploy a worker in a network close to your target infrastructure, simplifying network requirements for tools like Ansible.
Cycloid workers require outbound traffic to the Cycloid scheduler. Additionally, depending on your pipeline jobs, workers generally need access to Docker Hub for resource images and to your code repository.
Exhaustive List of Outgoing Traffic from the Workers
- SaaS console
- On-premises
| Required | Service | Destination |
|---|---|---|
yes | Scheduler API | https://scheduler.cycloid.io |
yes | Scheduler | scheduler.cycloid.io:32223 |
yes | Docker registry | https://index.docker.io, docker.io |
yes | Cycloid stack | https://github.com/ |
| Required | Service | Destination |
|---|---|---|
yes | Scheduler API | Concourse web https://<cycloid_scheduler>:8443 |
yes | Scheduler | Concourse TSA <cycloid_scheduler>:2222 |
yes | Docker registry | https://index.docker.io, docker.io |
yes | Cycloid stack | https://github.com/ |
Type of Workers
Scoped Workers Pool: Using the Cycloid SaaS platform, worker pools are scoped to an organization. This means that all pipelines of an organization will run on workers attached to it. If you create another organization, you will need to create a separate worker pool for that organization.
A worker pool can be attached to only one organization at a time.
Global Worker Pool: If you own your dedicated Cycloid platform, you can attach a pool of workers that will be used by all organizations. This can be convenient for providing a shared pool of workers for all your users.
A pool of scoped workers can be attached to only one organization, while a global worker pool is attached to all organizations. There is no way to attach a pool of workers to only a specified list of organizations.
Keep in mind that it's quite easy to attach either a scoped or global worker pool in Cycloid, so you can change your configuration as needed.
Worker tags
At setup you can define a tag for a worker. By doing that a worker with a tag will execute only pipeline jobs defined with the same tag. Tagging a worker allows you to specify which workers should execute certain tasks, ensuring that specific jobs run on appropriate or specialized workers. This can be useful for tasks that require particular dependencies, software versions, or hardware capabilities.
Example Use Case: If you have a pipeline task that performs heavy I/O operations, you can tag a worker with "high-iops" and configure the corresponding tasks in your pipeline to only run on workers with this tag. This ensures that the task runs on workers equipped with high-performance disks, providing the necessary IOPS (Input/Output Operations Per Second) to handle intensive data processing efficiently.
How to deploy






Troubleshooting
If your worker is not running correctly, you can follow the Troubleshooting section.