CI/CD pipelines
Cycloid CI/CD enables the creation of immutable pipelines, ensuring that each pipeline job build is based on a defined set of external resources and dependencies. This eliminates issues related to unpredictable changes in resources, providing a stable and reproducible build environment.
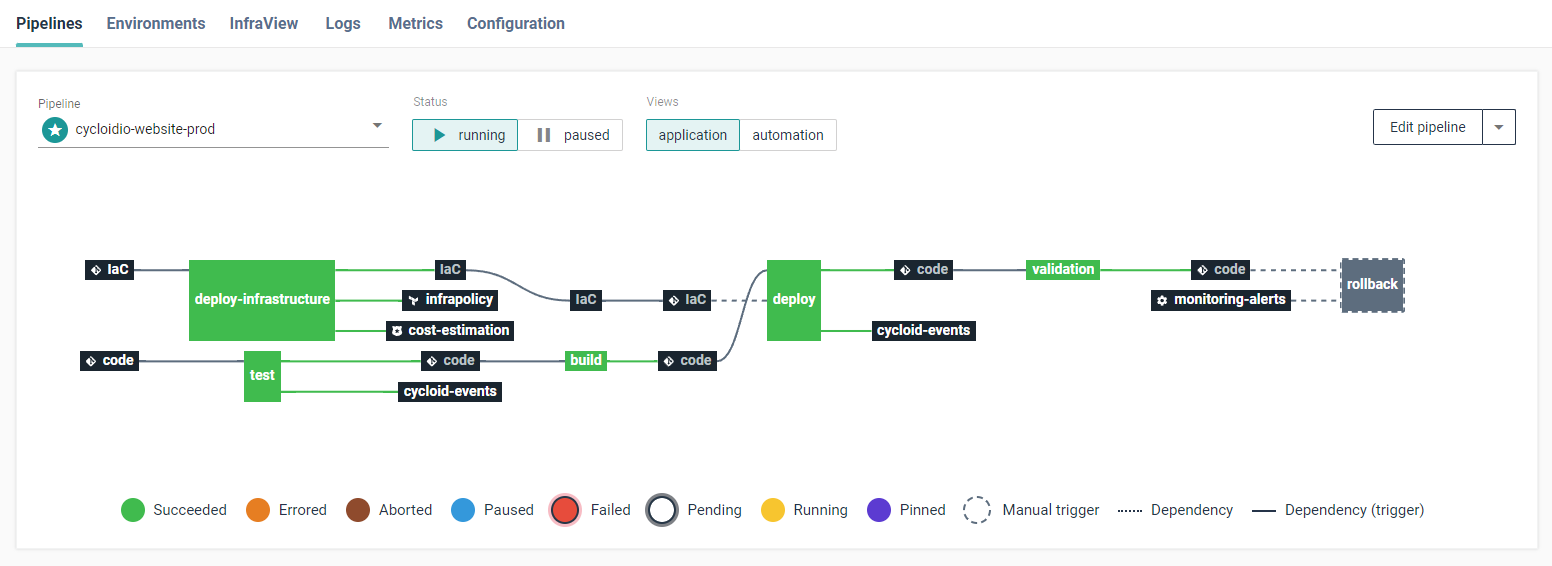
Our pipeline engine orchestrate an entire workflow through a visual interface.
You can use it to build an application, create an infrastructure, deploy an application, interact with monitoring tool, and all others steps you could imagine...
Our pipeline engine is based on the open-source Concourse CI software.
Introduction
A stack contains one or more pipelines. A pipeline describes an entire workflow, not only a CI/CD process. This means a pipeline can be triggered by any external components such as infrastructures, Docker registries, Git repositories, object storage, and more (referred to as resources).
In the Cycloid ecosystem, the process of merging stack configurations (as described in the stack concept documentation) is facilitated through a pipeline that listens to both the stack and configuration repositories within Git. Typically, our helper script merge-stack-and-config described later in this section, provided in the cycloid-toolkit Docker image, is utilized to accomplish this task.
Additionally, it can interact with these resources, for example, creating a Git commit or pushing a Docker image.
Pipelines are extended by resources and natively embed credential management using Hashicorp's Vault.
This offers a flexible way to describe and orchestrate the lifecycle of an application and infrastructure. Moreover, it provides the possibility to be used for operational automation purposes.
Our current pipeline engine is based on the open-source Concourse CI software. It brings flexibility and immutability through Docker containers. Pipelines are configured as code through a YAML definition.
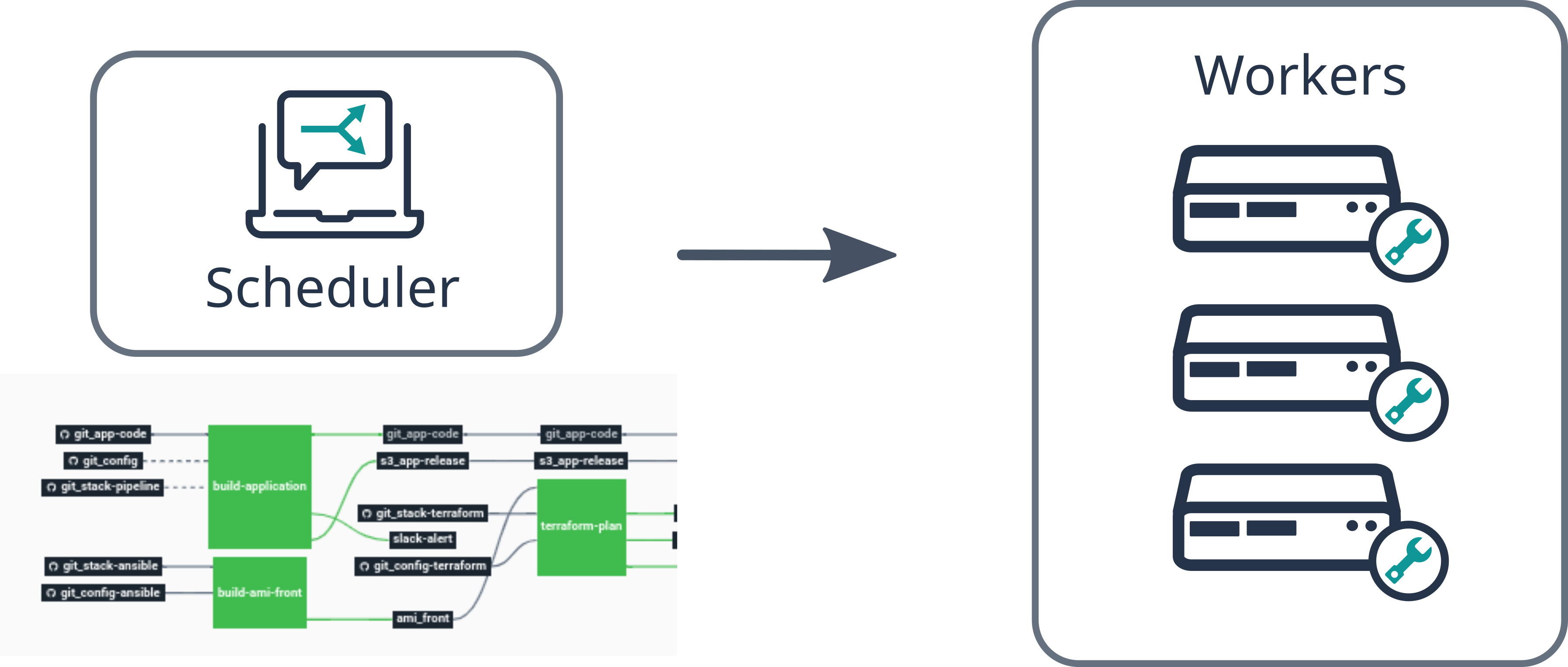
The pipeline engine is composed of two components:
- Scheduler: In charge of pipelines display and giving instructions to workers.
- Workers: The actual pool of servers running jobs and tasks described in a pipeline. More details are provided in the workers section.
Under the hood
One basic lexicon to understand about pipelines is the difference between what we call a pipeline template and a running pipeline.
- Pipeline template: This is the source code of the pipeline, written in YAML and stored in the Git repository of your stack.
- Running pipeline: When you create a project using a stack, it reads the pipeline template in Git, injects user input variables into it, and sends it to our pipeline engine (Concourse).
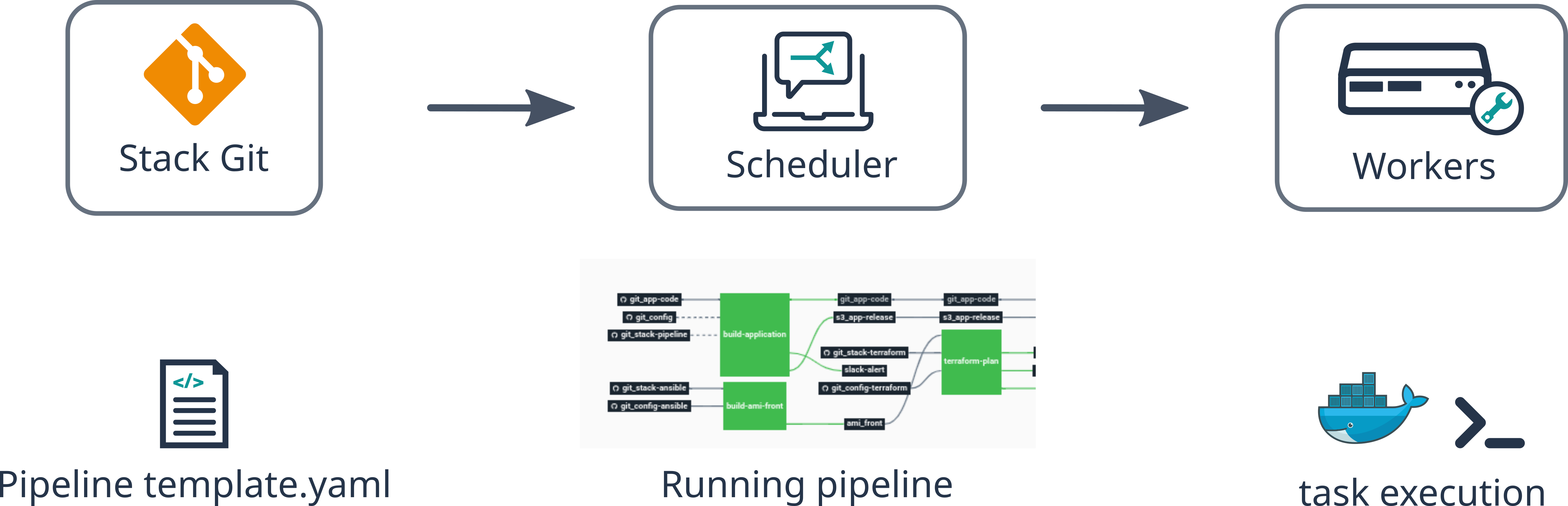
The template of a pipeline is contained in the stack repository. This template is used only when you create an environment. This means that if you edit the pipeline using the Dashboard, you are actually editing the running pipeline created from the template, not the template itself.
This also means that updating the template will not update the running pipelines that you have already created. To refresh your running pipeline using the latest version of the template, you can simply click on the refresh pipeline option in the pipeline view. Or edit the configuration with stackforms (in the configuration tab). By saving a new configuration it will also update the pipeline.
It's important to understand the difference between a pipeline template and a running pipeline.
Prerequisites
Before running a pipeline, you need to configure at least one worker for your Organization. If no worker is configured, attempting to run a pipeline will result in a "no worker available" error message.
If there is no worker for your current Organization, contact an administrator or connect one to your organization by following the Connect a worker section.