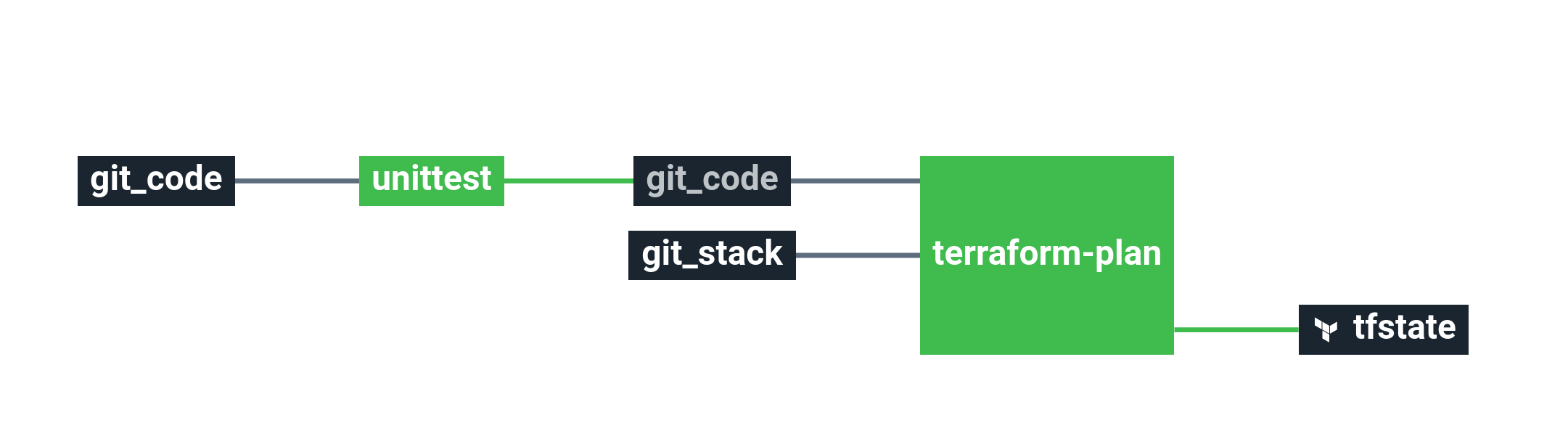
To complete this step, we will use what we previously saw in Step 2 by adding a new job to run Terraform if our unittest job succeed. The goal is to configure a new resource to run Terraform and use it in a dedicated job.
Additionally to that, the Terraform code will be stored in your Git repository, inside the stacks branch. This means we will also configure a git resource in the pipeline to get the content of the stacks branch.
Follow those steps to apply all changes described in this step
Starting with the Terraform code. Let's create a dummy Terraform configuration with the cloud provider we want to use for Terraform in a provider.tf file.
Several input variables have been defined to configure the cloud provider and two variables to pass the source code git repository URL that we will use and explain in the next step. The provider.tf usually also contain some generic variables like customer, project and env as most of our customer use them in Terraform to tag/name cloud resources.
Now add a Terraform resource into the pipeline. As Terraform is not part of the core resources type(opens new window) of Concourse, the first thing is to specify a new terraform resource type in the dedicated root section resource_types.
TIP
When to use a task or a resource in a pipeline?
In our case, we could have provided our container image with Terraform already installed on it and called the terraform command.
A resource usually is here to simplify a task. It makes something more generic and easy to use with embedded scripts. A resource also creates versions that can be used between different jobs as triggers.
From there, a new terraform resource type is available and can be configured. The following sample configures a resource called tfstate of our new terraform type:
Some explanations: Terraform stores the status of the infrastructure in a file called tfstate(opens new window). This file can be stored in different backends. In this example, we decided to use our cloud provider object store as backend type(opens new window) to store this file.
The backend_type parameter defines this, then configured in the backend_config section, using pipeline variables defined below. Refer to the dedicated Terraform documentation to know more about your backend storage configuration.
The vars section defines a collection of Terraform input variables(opens new window) provided by the pipeline. Variables are given by the pipeline to Terraform. The most common ones are the cloud provider credentials that we defined in provider.tf and the extra customer/project/env that we previously saw.
Small detour by variables.sample.yml file to add our new pipeline variables:
stack-sample/pipeline/variables.sample.yml
git_ssh_key: ((ssh_key.ssh_key))
# Branch used to store the config of the stackgit_repository: git@github.com:cycloidio/my_git_repository.git
stack_git_branch: stacks
# Aws access to use inside the pipelineaws_access_key: ((aws_step-by-step.access_key))
aws_secret_key: ((aws_step-by-step.secret_key))
aws_default_region: eu-west-1# Terraform tfstate storage Configurationterraform_storage_bucket_name: ($ organization_canonical $)-terraform-remote-state
terraform_storage_bucket_path: ($ project $)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
git_ssh_key: ((ssh_key.ssh_key))
# Branch used to store the config of the stackgit_repository: git@github.com:cycloidio/my_git_repository.git
stack_git_branch: stacks
# Terraform tfstate storage Configurationterraform_storage_container_path: ($ project $)/($ environment $)
terraform_storage_container_name: cycloid-demo
terraform_storage_access_key: ((azure_storage_step-by-step.access_key))
terraform_storage_account_name: ((azure_storage_step-by-step.account_name))
azure_resource_group_name: cycloid-demo
azure_location: francecentral
azure_env: public
azure_subscription_id: ((azure_step-by-step.subscription_id))
azure_tenant_id: ((azure_step-by-step.tenant_id))
azure_client_id: ((azure_step-by-step.client_id))
azure_client_secret: ((azure_step-by-step.client_secret))
git_ssh_key: ((ssh_key.ssh_key))
# Code repo configurationcode_git_public_repository: https://github.com/cycloid-community-catalog/docs-step-by-step-stack.git
code_git_branch: code
# Branch used to store the config of the stackgit_repository: git@github.com:cycloidio/my_git_repository.git
stack_git_branch: stacks
# Terraform tfstate storage Configurationterraform_storage_bucket_name: ($ organization_canonical $)-terraform-remote-state
terraform_storage_bucket_path: ($ project $)
gcp_project: cycloid-demo
gcp_zone:"europe-west1-b"gcp_credentials_json: ((gcp_step-by-step.json_key))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
We added several variables related to our pipeline changes.
git: to provide the SSH key to get Terraform code from your private git repository (git_ssh_key). As well as the branch and URL to use (stack_git_branch, git_repository)
cloud provider: to configure the cloud provider access and Terraform tfstate file storage.
As you can see, the value of some variables has a specific format ((myvalue)). For example, in line 1, the value of this pipeline variable will be provided by a Cycloid credential. The one you previously created in the section prepare Cycloid credentials. See pipeline variable documentation for more information to use Cycloid credentials into a pipeline.
Getting back on the pipeline file to configure a git resource to get the dummy Terraform source code from our stacks branch.
We also added a filter on Terraform path using paths to trigger terraform jobs only when commits change terraform files.
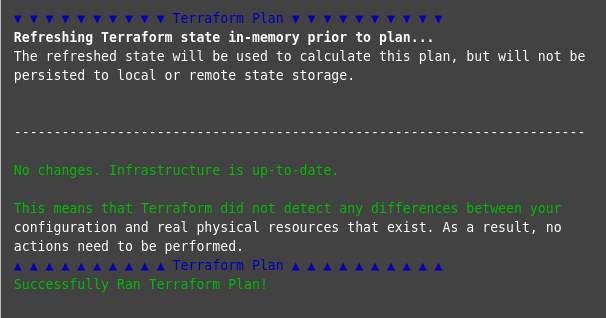
Standard pipeline behavior with Terraform is to run Terraform plan(opens new window). It's a convenient way to check the execution plan for a set of changes that matches your expectations without making any changes to real resources. Then create a second job to apply those changes by calling Terraform apply(opens new window).
Let's start and create the dedicated job to run terraform plan command just after unittest job (passed argument) and speak about terraform apply in the next step:
An important point is the passed parameter that you can put on get action. This keyword links jobs together to ensure that we will get the code already processed by the unittest job.
This job gets Terraform code from git_stack resource, which is our git on the stacks branch. Then call put(opens new window) on Terraform resource (tfstate) using plan_only parameter to specify that we want only to run terraform plan.
As Terraform is not part of the core resources type(opens new window) of Concourse, the first thing is to specify a new terraform resource type in the dedicated root section resource_types
Terraform stores the status of the infrastructure in a file called tfstate(opens new window). This file can be stored in different backends
 .
.