# Configuration
WARNING
This section is made short on purpose, because it would not make sense to paraphrase Concourse's documentation; as Cycloid is based on Concourse, the concept of pipeline (opens new window) is defined by Concourse itself.
A pipeline is a definition of jobs (opens new window) and resources (opens new window) within YAML files.
Jobs execute tasks (opens new window) first based on the versions (opens new window) of resources given as inputs (opens new window).
For example a time resource (opens new window) could trigger a job every day at 12PM, whereas a git resource (opens new window) could trigger a job based on the commits/tags/branches of a git repository. These resources can also be used to do actions: report status on git repository (opens new window) or notify a slack channel (opens new window).
During their executions jobs can alter resources to create artifact outputs (opens new window). These outputs can be directly given to other jobs or be used later on.
You can visit other sections of our documentation for a better understanding such as the pipeline examples, or create your first private stack.
Feel also free to visit our community catalog (opens new window) for complete example of stacks using various common softwares.
# Refresh a running pipeline from the template
Running pipelines can shift from a template, because you updated the template or you edited directly the running pipeline using the Cycloid dashboard.
If you feel the need to sync back your running pipeline from the template in the stack :
- Simply go on
Pipelinesview. - Select the desired pipeline.
- Click on top right
Reset pipelinebutton. - A wizard will display the code of the pipeline and the variables from the sample in the stack.
- Make sure you enter the right values in the variables
- Click on
Save
TIP
We currently recommend to backup the variables you provided to configure your pipeline to help you if you reset it.
Note : We are currently working on a feature provide the value of the variables from your running pipeline during a refresh.
# Understanding a pipeline display

A pipeline contains resources (black) and jobs (green). A resource is for example a git repository.
The resource is linked to a job in this example terraform plan. The full link
 indicates that the plan job will
automatically trigger if a new git commit is detected by the resource. But in
some cases like above for the terraform apply job, there is only dot link
indicates that the plan job will
automatically trigger if a new git commit is detected by the resource. But in
some cases like above for the terraform apply job, there is only dot link
 which means that nothing will
automatically trigger this job.
which means that nothing will
automatically trigger this job.
We usually use this to do some kind of “approval” to let the user validate the output of the plan, then trigger manually the apply of terraform. To do that just click on the apply job and press the "+" button to trigger the job.

To know the details of a build, just click on a job. It will display each steps done, the status and also each resource version (git commit, ...) used during this build.

TIP
See more about pipelines format here :
# Special Cycloid variables
If you are creating your own stack, you might be looking for a way to add some bits of templating on those files.
Cycloid console provides a minimal templating to share information like the project name or the env name of a stack, ... in variables and sample files of your stack.
To use it, it’s really simple, you can define those keywords:
($ environment $)
($ project $)
($ organization_canonical $)
2
3
Those variables are usable in Stackforms or in the code editor mode. To get the full list of available variables, check stackforms documentation
# Style guide
# Reduce log outputs
Some standard commands used in pipelines generate a lot of output lines or progress bars. Which makes the whole build log output sometimes hard to read. To reduce this output, this is our tips for common commands :
# Apk
apk add -q --no-progress ...
# Curl/wget
curl -s ...
wget -q ...
2
# Pip
pip -q install ...
# Easy_install
easy_install --quiet ...
# APT
apt-get update -qq > /dev/null
apt-get install -yqq ... > /dev/null
2
# Npm
npm install --silent
npm build --silent ...
yarn install --silent
2
3
# Php-composer
composer -q ...
php composer.phar install -q
2
# Ansible / Packer-ansible
Make sure all ansible command are prefixed or have this env var ANSIBLE_STDOUT_CALLBACK=actionable to use callback/actionable - shows only items that need attention (opens new window)
Same case for Packer, make sure all shell commands also respect the points above (apt, ...)
Eg the packer.json for the ansible call
{
...
"type": "ansible-local",
"command": "ANSIBLE_STDOUT_CALLBACK=actionable ANSIBLE_FORCE_COLOR=1 PYTHONUNBUFFERED=1 ansible-playbook",
...
}
2
3
4
5
6
# Use bash trap in scripts
One of the pattern is to kill a process faster, when a job succeeds or fails and control better the log output. So that you can display a simple "OK" when everything went fine, or the full logs when it failed.
This is a dummy example that you can put at the beginning of a script in a task, which illustrates a way to implement it:
path: /bin/bash
args:
- -ec
- |
function finish {
if [ $rc != 0 ]; then
echo "Build finished with error, displaying the verbose log file ..."
cat verbose_log_file
fi
}
trap 'rc=$?; set +e; finish' EXIT
... doing some stuff ...
make test > verbose_log_file
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Define global and default variables to tasks
As you might have already learned in our create my first private stack guide, we can use YAML Alias indicators (opens new window) to reduce the size of pipeline templates.
The code below uses theparams field in the task and config sections of the pipeline template to provide local and global variables.
shared:
- &task-template
config:
platform: linux
image_resource:
type: docker-image
source:
repository: busybox
params:
GLOBAL_MESSAGE: Common message to all tasks
run:
path: /bin/sh
args:
- '-ec'
- |
echo "Global message: ${GLOBAL_MESSAGE}"
echo "Local message: ${LOCAL_MESSAGE}"
echo "Default message ${LOCAL_MESSAGE:-$GLOBAL_MESSAGE}"
jobs:
- name: job-hello-world
build_logs_to_retain: 3
plan:
- task: foo
<<: *task-template
params:
LOCAL_MESSAGE: Here is a local message from foo
- task: bar
<<: *task-template
params:
LOCAL_MESSAGE: Here is a local message from bar
- task: bli
<<: *task-template
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
This is a good example of how to share the code across several tasks and be able to specify custom params for each of them.
As shown on Line 20, by using some bash's parameter substitution syntax (opens new window), we can use an optional params local variable given by a task as a way to override the default global value.
# Common pipeline errors
# Job/task : invalid tag format
Error message :
Error
resource script '/opt/resource/check []' failed: exit status 1
stderr:
failed to construct tagged reference: invalid tag format
2
3
4
This error usually occurs because of a typo in the docker image name which contain also the tag :
- task: foo
config:
image_resource:
source:
repository: docker:dind
2
3
4
5
Solution
Use the expected tag field in pipeline configuration to provide a specific docker image.
source:
repository: docker
tag: dind
2
3
# Job/task : 401 Unauthorized
Error
resource script '/opt/resource/check []' failed: exit status 1
stderr:
failed to fetch digest: 401 Unauthorized
2
3
4
This error usually occurs because the docker image specified does not exist on dockerhub :
source:
repository: docker/foobar
2
Solution
Ensure the image specified is a valid one using docker pull docker/foobar
# Resource/Job : Expected to find variables
Error
Checking failed
Expected to find variables: ssh_access
2
3
Which mean the pipeline is looking for a variable or a credential which is not configured.
It could come from a missing variable defined into your pipeline and not in the variables.sample.yaml.
Or most of the time it come from a missing credential required by the pipeline. See more about credentials here. And how configure and use it into a pipeline here.
This error usually occurs because the docker image specified does not exist on dockerhub :
- name: git_master
type: git
source:
private_key: ((ssh_access.ssh_key))
2
3
4
Solution
In this case the solution was to create a new Cycloid credential named access of type ssh in our organization.
# Troubleshooting
# Connect in a pipeline running container
A build is an execution of a build plan, which is either configured as a sequence of steps in a job, or submitted directly to Concourse as a one-off build via fly execute.
Containers and volumes are created as get steps, put steps, and task steps run. When a build completes successfully, these containers go away.
A failed build's containers and volumes are kept around so that you can debug the build via fly intercept. If the build belongs to a job, the containers will go away when the next build starts. If the build is a one-off, its containers will be removed immediately, so make sure you intercept while it's running if you want to debug.
https://concourse-ci.org/builds.html#fly-intercept (opens new window)
To use fly intercept in Cycloid start to get the required information:
Note
To get CY_ORG_TEAM, click on the name of your Organization within the left menu  and copy the
and copy the ci_team_member value.
export CY_ORG_TEAM=
export CY_PROJECT=
export CY_ENV=
export CY_PIPELINE_JOB=
# Specify the Concourse URL
# For onprem setup
export CONCOURSE_URL=http://<Onprem address>:8080
# For SaaS users
export CONCOURSE_URL=https://scheduler.cycloid.io
2
3
4
5
6
7
8
9
10
Then simply connect on the running container using fly cli:
# Get Concourse fly cli
curl -JO "$CONCOURSE_URL/api/v1/cli?arch=amd64&platform=linux"
chmod +x fly
# Login and connect on the running container
fly --target $CY_ORG_TEAM login -n $CY_ORG_TEAM --concourse-url "$CONCOURSE_URL" -k -u admin -p admin
fly --target $CY_ORG_TEAM intercept -j "${CY_PROJECT}-${CY_env}/$CY_PIPELINE_JOB" sh
2
3
4
5
6
7
# Manually re-trigger a pipeline build
There are case when a pipeline fails for temporary reasons or causes external to the environment you have under control. In such cases it is possible to manually re-trigger the pipeline once the external or transitory issues are solved.
Briefly the steps needed are:
- Pin the resource version
- Re-trigger the pipeline
- Unpin the resource version once the pipeline started
In more details to pin a resource version you have to click on the resource in the pipeline visualization page. For example in the picture below you can click on the git_stack-ansible box to access the history of version of that resource.

Clicking on the resource brings you a list of versions for the selected resource, see picture below.
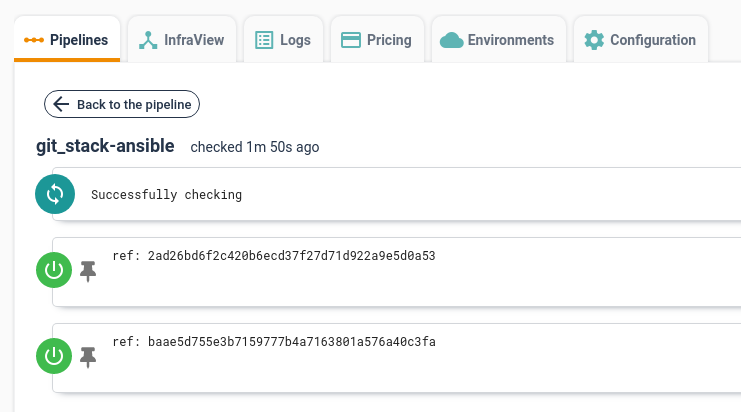
In this view each line represents a version of the resource. And in each line there is a 'pin' icon, clicking on the icon pins the resource version, a pinned version will be used for the next executions of the pipeline.
The figure below shows a pinned resource version.
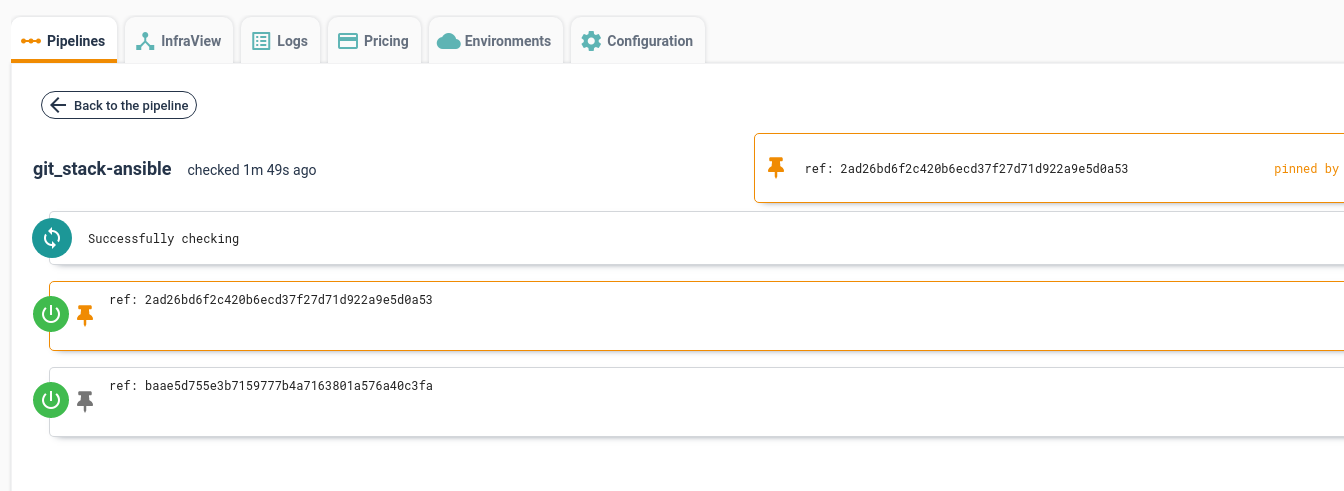
Going back to the pipeline view, we can notice that the pinned resource is highlighted in purple, as shown in the figure below.

All that is left now is to manually trigger the job as explained as before in this section, clicking on the green box representing the job getting the pinned resource and then on the "+" icon.
Beware that all the next executions of a job will use the pinned version of a resource until it stays pinned. It is advisable to unpin it after the job starts.
# Common errors
An issue has been identified where pipeline logs are not displayed. Or not fully displayed.
The pipelines logs are get through an api call called /events of type event-stream.
If your pipeline don't display logs the issue usually could come from a proxy server not allowing this type of traffic. We also saw this behavior with Netscaler and HTTP compression (opens new window) configuration.