# Concepts
# General concepts
# GitOps
Cycloid uses the concept of Stacks in a full GitOps approach leveraging infrastructure as code where the automation is owned by your DevOps team.
GitOps works by using Git as a single source of truth for declarative infrastructure and applications. With Git at the center of your delivery pipelines, developers use familiar tools to make pull requests to accelerate and simplify both application deployments and operations tasks.
In addition to stacks, Cycloid offers various features to take full advantage of a GitOps approach:
Infra Import can help your DevOps team to create your automation from an existing infrastructure
# Infrastructure as code (IaC)
# Overview
Infrastructure as code (IaC) is the process of managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. There are many tools that fulfill infrastructure automation capabilities and use IaC, whether at the infrastructure level:
| Example tools | Description |
|---|---|
| Terraform (opens new window) | An open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services |
| AWS Cloudformation (opens new window) | A template describes your desired resources and their dependencies so you can launch and configure them together as a stack |
| Google Cloud Deployment manager (opens new window) | An infrastructure deployment service that automates the creation and management of Google Cloud resources |
| Azure Resource Manager (opens new window) | A deployment and management service that provides a management layer that enables you to create, update, and delete resources in your Azure account |
Or at the application and configuration management level:
| Example tools | Description |
|---|---|
| Ansible (opens new window) | The simplest way to automate apps and IT infrastructure. Application Deployment + Configuration Management + Continuous Delivery |
| Puppet (opens new window) | Manage and automate more infrastructure and complex workflows simply and powerfully |
| Chef (opens new window) | Powerful Policy-Based Configuration Management Automation Software for DevOps Teams |
| Salt-stack (opens new window) | Building intelligent, event-driven automation software (ITOps, DevOps, NetOps or SecOps functions) |
# Drawbacks
These days, IaC makes a lot of sense, but there are some small drawbacks to consider.
For example, the initial setup may take a little longer than usual, because you have to make sure that everything you did has been written down as code for both your infrastructures and/or code. Small changes can also prove to be slower than manual ones: changing a DNS entry could be very quick in a console, but would require you to find the file referencing that DNS entry, update & commit it, and apply the changes.
Those drawbacks are difficult to erase, but IaC comes with a lot more benefits.
# Benefits
As previously mentioned there are many benefits from using IaC.
First of all, via the automation of your IaC you make your day to day operations much more robust and reliable, as you reduce the human error factor. This automation could also come in handy if you need to automatically document your infrastructure, as everything is already written down.
With that automation enters the logic of continuous delivery and collaboration. As everything is automated, you will want to version this code, allowing you to gain better knowledge over your infrastructure.
Everything is now shared, with an history of what has been done, what is currently configured, who applied the changes, who required those changes, etc.
Due to this automation, your infrastructures and environments are now more reproducible (it becomes much easier to create a new one), less likely to environments shifting (or if so, better managed), reusable for other projects, and better controlled.
Taking advantage of the flexibility of the cloud and IaC, you will have a better control over the cost of your infrastructure based on your usage. You can also easily scale up or down, start/stop environments that you do not use at night or during development phases, etc.
If you wish to read more about it, various actors are speaking about it too, such as Microsoft (opens new window), Hashicorp (opens new window) or Puppet (opens new window) for example.
# Cycloid concepts
# Stacks
# Overview
Cycloid recommends the usage of Infrastructure as Code and invites you to organize this code using the concept of a Stack.
A stack is a way to build and organize your infrastructure as code and files. There is nothing required, it's up to you to follow and apply it to any tools and software or not.
The global idea is to create a generic description of your application that you will use across all your projects and environments. Exposing to the end users only a few configurable parameters, based on their needs.
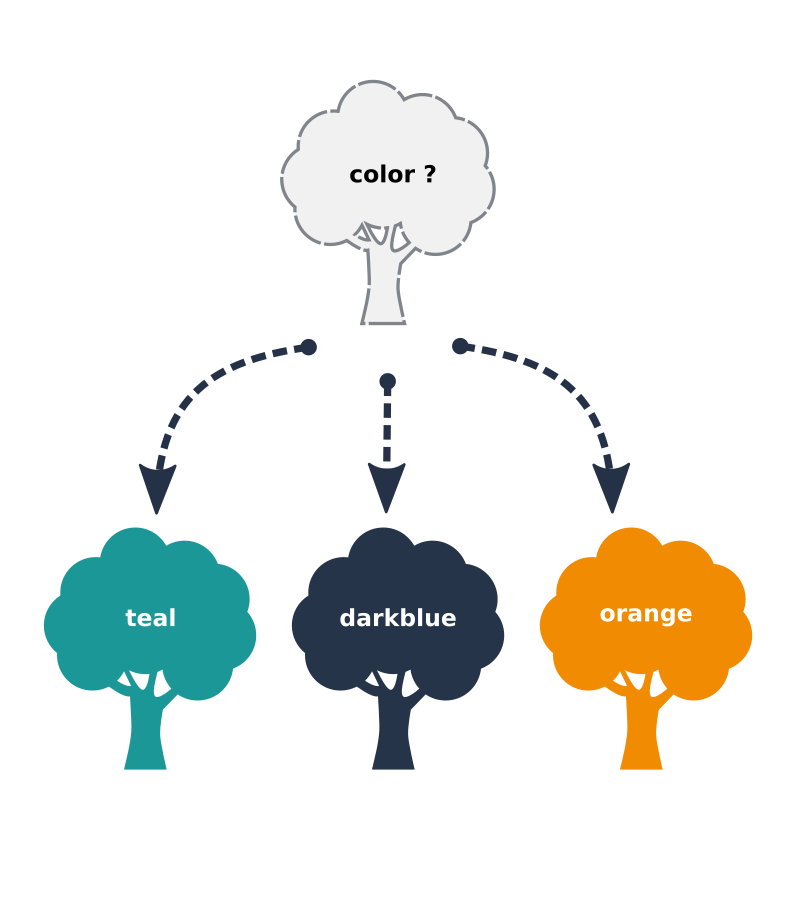
Let's give a simple example with a tree. From a Cycloid point of view, the stack would be the definition of the shape of the tree. A tree will be composed of roots, a trunk, branches, and leaves on top of it.
Unfortunately not all your users ask for the exact same tree, each one wants a different color.
This is where Cycloid speaks about config for a stack. In our tree example, we could imagine a color parameter in the stack letting the user chose the color of his tree.
This way all trees will share the exact same shape defined in the stack and a color defined by the user in his config.
To achieve it from a technical point of view, we speak about stack and config:
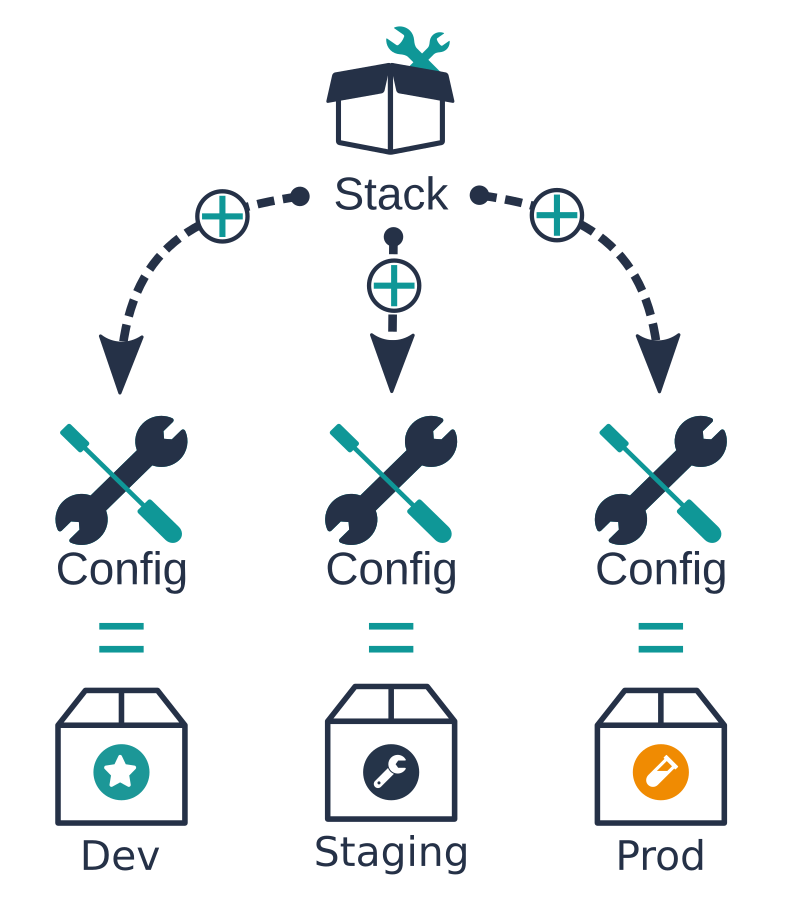
The result of a merge between the stack and the config is called a configured stack.
When a user creates an environment into a project it will consists of selecting a stack and provide a configuration to deploy a configured stack.
To understand a little bit more what do we expect to find in those 2 sections, let's use a basic example of a LEMP stack (opens new window):
- A
stackis a generic description of an application. You should put here everything common between all environments of this stack. In our example, we will define using IaC servers on which we install an Nginx web server and PHP, connected to a database. - The
configgives all related configuration to an environment (dev, staging, prod for example). In our LEMP example, the number and the size of the servers to create.
Basically in a project, you might want staging environment to be the same as the production one but, with smaller servers size to limit the cost. Using the stack concept, all environments will share the same stack but use their own dedicated config to specify the various sizes of the environment.
Cycloid usually works with a stack and config definition stored in a Git repository, created respectively in stacks and config branches. Stack and configuration definition could be in a public or private Git repositories.
# Structure
Cycloid Framework is here to make the glue and the integration between technologies. Most of our stacks are based on OpenSource technologies such as these.
| Technologies | Description |
|---|---|
 | Stores and versions the logic and configuration of a stack |
 | Describes the infrastructure and services used |
 | Deploys and configure applications inside the target |
 | Provides pipeline view and scheduler for the CI/CD jobs |
It is not mandatory to use all those parts, for example if your stack goal is only to create infrastructure via Terraform, you can ignore Ansible.
Note
You can also use other technologies (e.g.: Salt, Puppet, Chef, etc.) adapted to your needs, feel free to ask Cycloid engineers for some help
# Catalog repositories
A catalog repository is one of your Git repositories, you can use it to create and store your stacks. You can add public and private Git repositories, however for private Git repositories you will need to provide the corresponding credential.
# Config repositories
A config repository is one of your Git repositories, you can use it to store your stacks configurations (or config). You can add public and private Git repositories, however for private Git repositories you will need to provide the corresponding credential.
# Credentials
Cycloid Credentials manager store secrets that you need. With this, you can store, access and distributes secrets like API keys, AWS IAM/STS credentials, SQL/NoSQL databases, X.509 certificates, SSH credentials, and more.
# Environment
Because your projects are automated and reproducible via IaC, environments can be seen as versions of your projects.
Usual common environments naming are dev, staging, preprod & prod, but those are just common names and could be of any kind. So an environment will be a call to your IaC tools with different parameters.
# Pipeline
The core element of a stack is a pipeline. Each stack contains a template of a pipeline and a sample of variables.
A pipeline describes the workflow of a stack, how to create the application and also how to automate and orchestrate the deployment of new releases.

Each stack contains a YAML template of the pipeline and a sample of variables to configure it. When you create a project from a stack, the template is read by Cycloid to create a running pipeline.
You'll learn more about the Pipeline deployment in the Manage section.
# Workers
Workers are used to execute pipeline jobs and perform resource checks. Having at least one worker is mandatory for your pipelines to work.
The pipeline engine used in the Cycloid platform is composed of 2 components:
- Scheduler: Server-side on which workers are connected. It schedules pipeline jobs and spreads tasks across your workers.
- Workers: Controlled by the scheduler to run the jobs of your pipelines.
You can learn more about Worker deployment in the Manage section.