# Stack additional design
As described in the previous section, stacks can be really handy to manage infrastructure, deployments or CI/CD jobs.
But it's important to keep in mind a pipeline in a stack can described much more. A pipeline describe a workflow to automate or simplify any actions.
You can nearly automate or describe any workflow in a pipeline. The resource approach of a pipeline allow you to interact with mostly all existing external software. More details about pipeline specificities and configuration will be given in the dedicated pipeline section.
The following sections will illustrate some internal and customer usecases where stacks and pipelines are used for not common usecases.
# Cycloid demo
As you could imagine at Cycloid we use the stack approach for everything. This is also the case for our demos. Through this usecase we will illustrate an automatic cleanup of infrastructure.
We created a small stack based on Terraform to deploy a WordPress application on several Cloud providers.

Then after a demo, when it comes the time to clean and destroy everything that have been created we decided to handle everything as part of the pipeline stack.
For this purpose we created a dedicated job which is triggered automatically one hour after a demo.
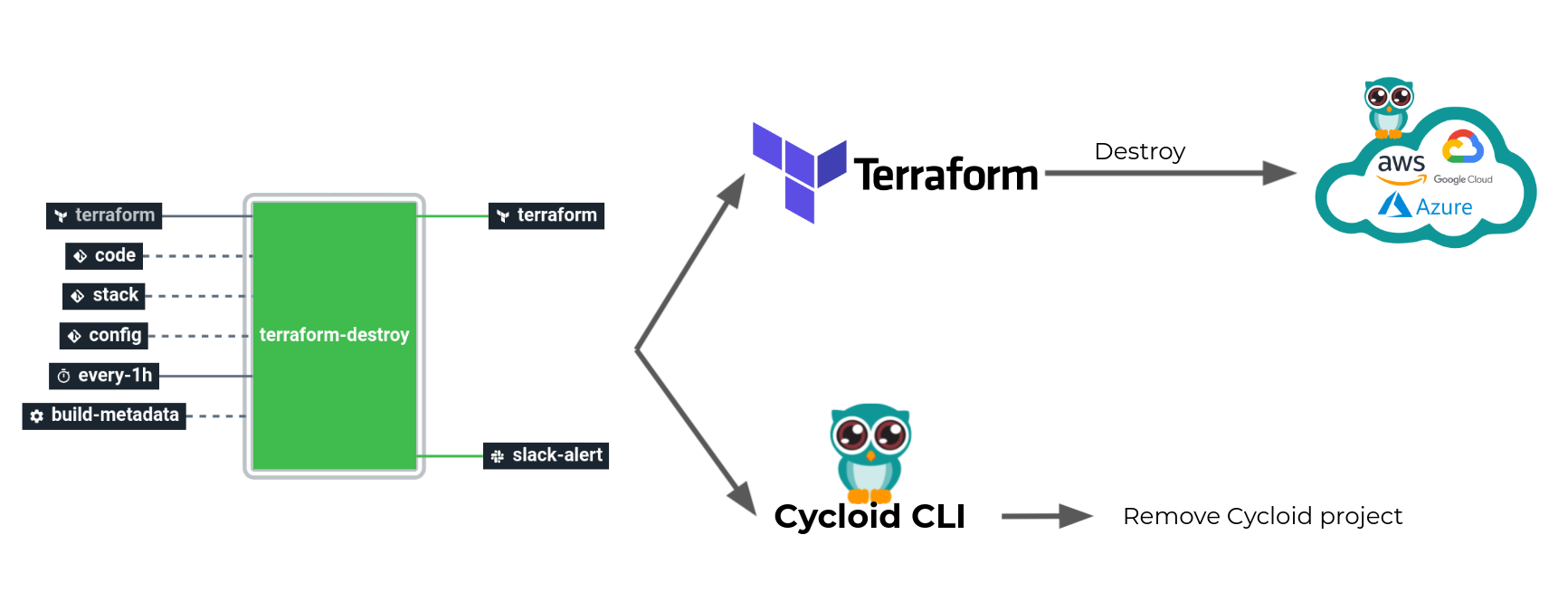
This job will use Terraform to destroy all cloud components that have been created. But also use Cycloid CLI to interact with our API and remove the Cycloid project created.
This way after a demo, everything that have been created on the Cloud provider and Cycloid side are deleted automatically.
# Feature branch (dedicated env)
Automatically create a dedicated environment for your developers.
Internally at Cycloid we use Github and pull requests workflow.

For each new pull request a dedicated test environment is created.
Going a bit deeper, everything start by creating a Cycloid project for our automation, let's take the example with our frontend application. This project is composed of several pipelines/environments.

Part of the list of all environment, there is one called github. This one contain the following special pipeline.

We call this pipeline a watcher. This pipeline take as input Github pull requests.
Each time a new pull request is created, the pipeline is automatically triggered and the job create-dedicated-env actually add a new environment to the previous project cycloid-frontend using Cycloid CLI.
The environment named is based on the Github pull request ID PR_<pull request id> and contain a standalone pipeline to create and deploy a temporary infrastructure.
This workflow could be sumup this way:
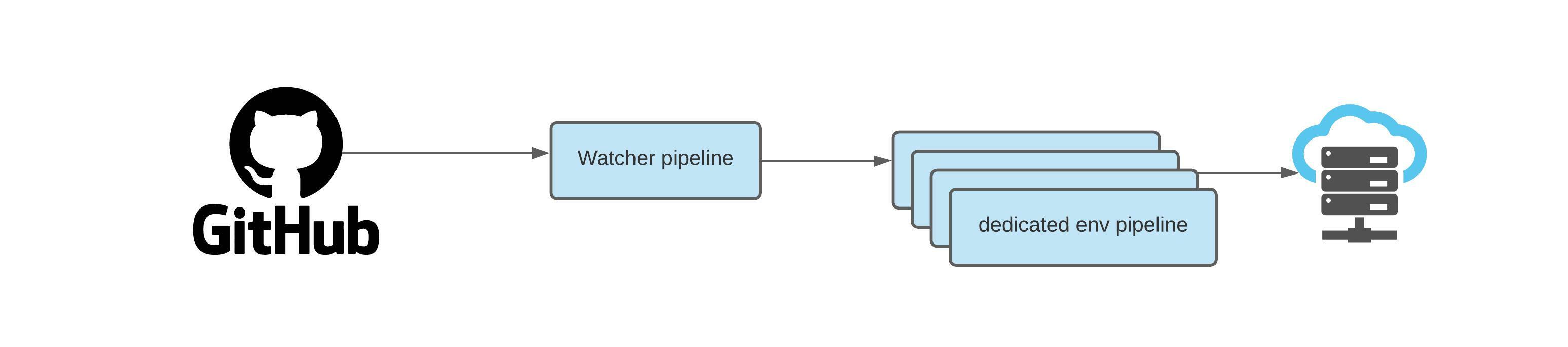
Our watcher is triggered by Github pull request. The watcher pipeline create for each pull request a dedicated env pipeline. The dedicated env pipeline handle the deployment and the creation of the temporary infrastructure.
The feature env pipeline looks like this:
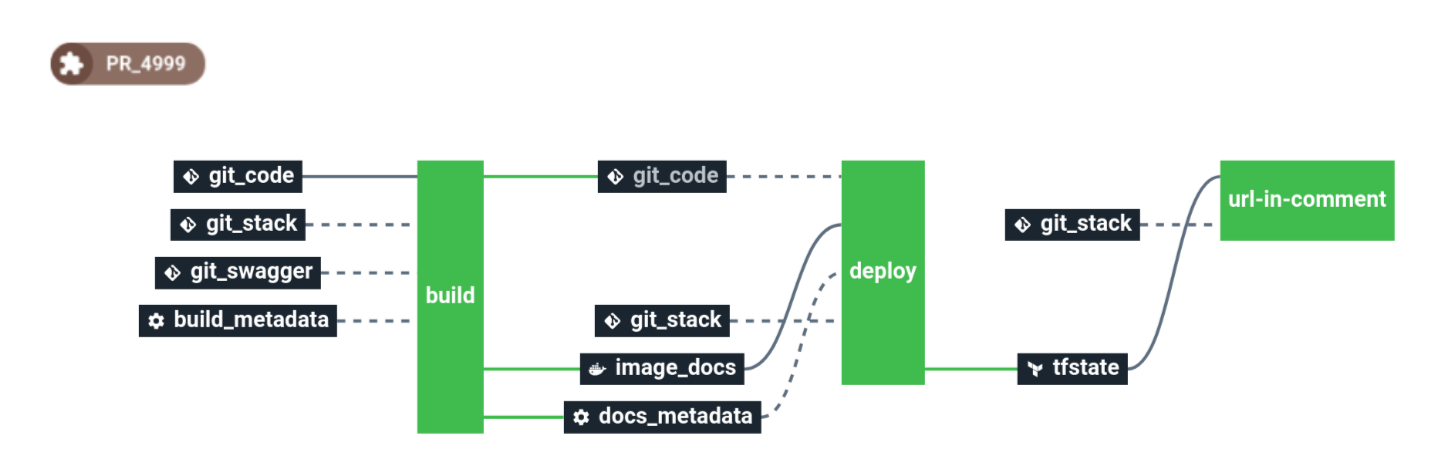
This pipeline create a dedicated infrastructure using Terraform. Then the pipeline listen for each git commit. And each time a new commit is detected, it build the code and deploy it on the dedicated infrastructure to test the code in live.
The last job of this pipeline is to send a Github notification to let our developers know the environment is up to date with the latest code

Last part of our workflow is automatic cleanup. For this purpose we use the same method described above in Cycloid demo usecase. The dedicated env pipeline contain a self cleanup job:
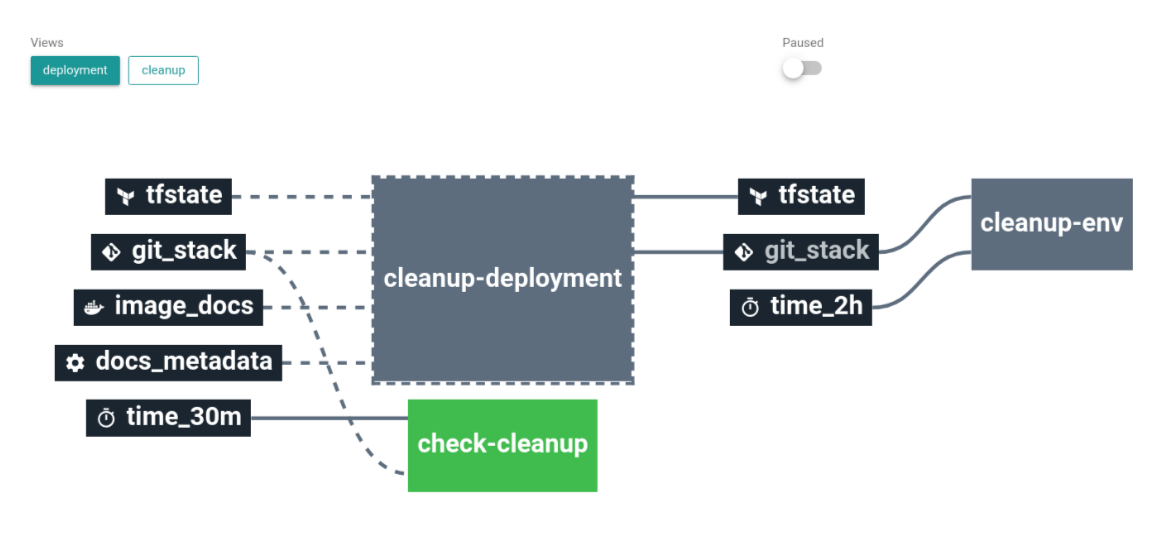
This job ensure each time the Github pull request is merged, the dedicated infrastructure is automatically destroyed using Terraformn. And the Cycloid environment is removed using Cycloid CLI.
# Simplify daily work
As described in previous use-cases pipeline can handle and automate complexe workflow. But it's important to keep in mind pipeline can be really simple and solve/automate basic needs.
TIP
Pipelines are not restricted only to CI/CD or infrastructure management.
A lot of small daily actions can be automated or simplified for your users by a pipeline.
An approach is to create automation or a dedicated job that a user could trigger to do a simple task. For example setting on/off a maintenance page on a website:

This example come from one of our customer need. He wanted to be able in one click to set his entier infrastructure in maintenance mode. Which involve to run Ansible on several servers. To solve this need we created a dedicated job, when triggered it run Ansible with the expected arguments, then send a Slack notification to warn users that the job have been done.
This is just one example from a huge list. Anything you have in mind could be simplified and automated by using a pipeline.
To give you other real life example of we our customers are doing with pipelines:
- Flush application cache (CDN, Varnish, …): Force the flush of entire CDN and Varnish cache of an application in one click.
- Automatic rollback of a deployment
- Based on functional testing: Run automatically functional tests after a deployment. And trigger a rollback if a failure is detected.
- Monitoring events: After a deployment, listen for monitoring alerts, if criticals are raised trigger a rollback.
- In case of deployment failure: Simply automatic rollback in case of deployment failure.
- Start and stop of servers or services: In one click offer the ability for someone not technical to stop servers or services.
- Enable/disable monitoring: Disable specific monitoring alerts during a deployment, then enable them again after the deployment.
- Trigger backups before deployment: As part of application deployment workflow, trigger a backup of the current application files or database before deploying the new one.
- Dump prod to staging: Automate prod database dump, data conversion then inject the dump on staging database.
- Release watcher: Follow a software and warn your user when a new release is done.
- Internally we use a lot a release watcher as we have several features based on Terraform. It allow us to always be warned for new Terraform release. Each time there is a new release, a chat message is sent to our internal developer channel.
# Gitlab as CI and Cycloid as CD
This use-case show how Cycloid could cohabit with CI tools. Sometime you want to handle a global and complexe workflow using Cycloid. But keep the local developement CI managed and handled by your dev team with the tool they used to work with.
- Let's take the example of a Docker Application.
- The goal is to deploy this application on Kubernetes.
- CI should test and build Docker images using Gitlab.
- CD should deploy each new docker images using Cycloid.
Keep in mind as best practice we recommand to use Infrastructure as code for everything. So in the use-case above as described in Designing a Stack, the good approach is first create a stack to manage and handle the Kubernetes cluster that we will use.
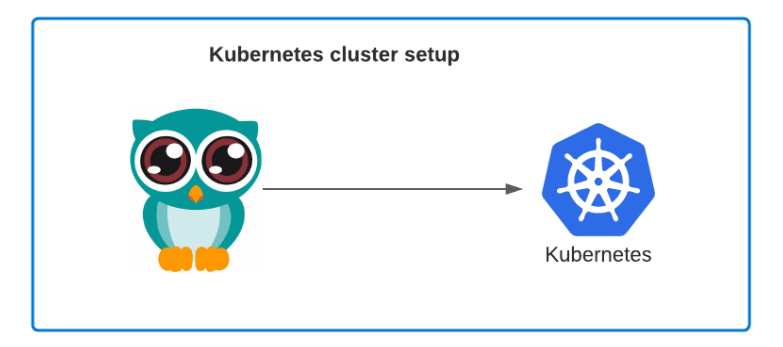
Then we can think of the actual use-case this way:
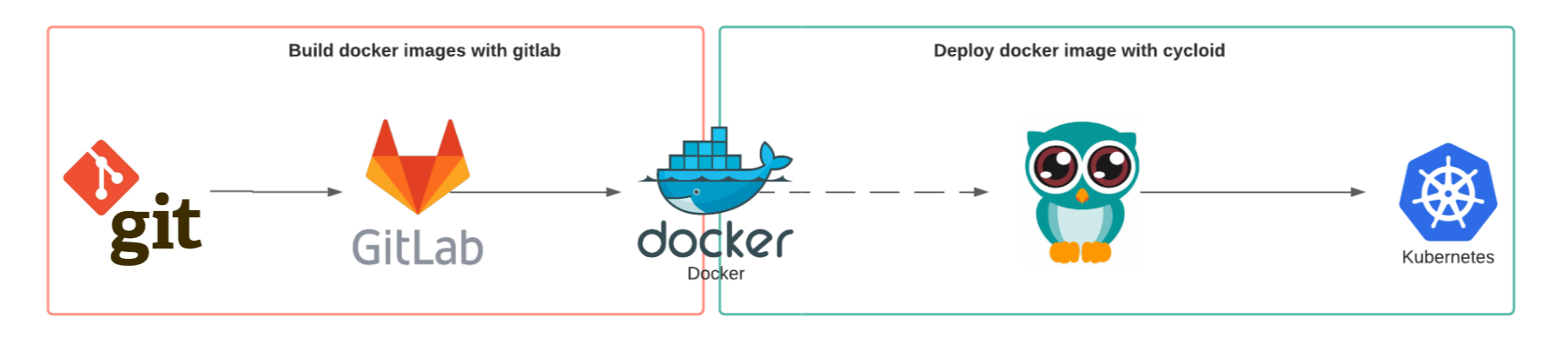
- The application source code is located in a Git repository.
- CI a Gitlab CI pipeline will handle the run of unittest and the build of the Docker image.
- The docker image is pushed into a Docker registry
- Cycloid pipeline listen Docker registry changes
- CD each time the Docker image is updated trigger a deployment
# Access management at Cycloid
As described earlier stacks are not limited to infrastructure. At Cycloid we tend to apply infrastructure as code and stack concepts for all our needs.
And access management is not an exception. We created a stack called IAM (Identity and Access Management).
This stack is pretty simple, it use Terraform to manage access to most of our services like Public cloud providers (Scaleway, GCP, Azure, AWS, ...) but also lot of others tools like Github.
# Kubernetes at Cycloid
We use to speak about infrastructure and basic application deployement but at Cycloid we use also Kubernetes. Most of our services are deployed on Kubernetes and managed by the Cycloid platform.
There is several approach to handle and manage it with Cycloid. Our way to do might evolve in the future but let's see our current approach.
Cluster management
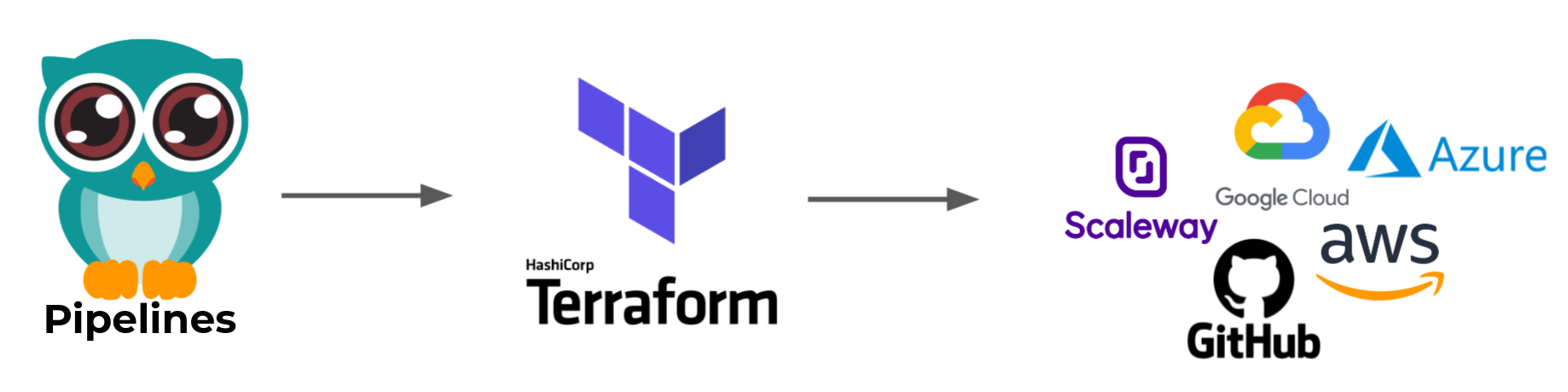
Everything as usual start by a stack to manage our Kubernetes cluster on Scaleway (Kapsule) using Terraform.
Docker image build
The stack approach is also applied to build docker images.
- For complexe or big application a dedicated CI/CD pipeline is wrote and used.
- For small standalone project like a git composed of a Dockerfile, we relay on our Docker build stack.
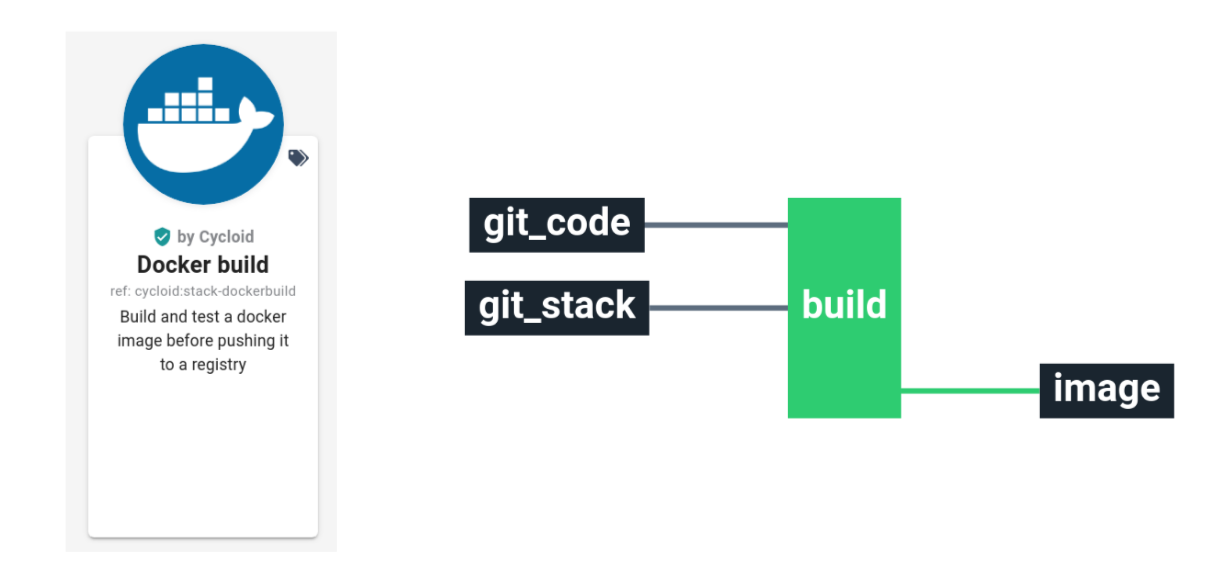
This stack use a git repository as input. Build a Docker image from a Dockerfile, then push it into a Docker registry.
Deploy on Kubernetes
Internally we use three main approaches to deploy on Kubernetes.
All those approach are part of a stack as well but the way we do depend of the need.
- Raw YAML files based on the kubectl Concourse resource (opens new window)
- Useful when you just want to deploy a Kubernetes YAML files found on internet
- If you want to write yourself a YAML files for advanced usages
- Terraform with the Terraform Kubernetes provider (opens new window)
- Useful when you want to manage cloud provider resources in parallel of your k8s one. For example if your application need a database that is managed by a public cloud provider. You can define dependencies between your application and cloud services
- Get the advantages of Terraform plan which is able to display a all changes that are going to be applied
- Helm through the Terraform Helm provider (opens new window)
- Use Helm charts from internet. If you just deploy an upstream application which provide helm charts
- Get the advantages of Terraform plan / diff
- Deal with Cloud provider resources dependencies like above
We use prefer the Terraform related solution to manage Kubernetes deployment as part of others infrastructure resources dependencies.
Note
Usecases presented here are only examples of the endless possibilities offered by Cycloid!